La mémoire opaque des LLMs, celle qui "s'améliore avec l'usage" sans que tu saches comment, commence à se faire remplacer par quelque chose de plus honnête. Des fichiers Markdown. Du git. Des trust scores. @karpathy a posté sur Farzapedia, un wiki personnel géré par LLM, et la communauté a répondu avec des implémentations qui tournent déjà en prod.
La mémoire explicite plutôt que la magie noire
L'argument de @karpathy est simple : une mémoire IA qui se construit dans un fichier que tu peux lire, éditer et versionner vaut mieux qu'un système opaque qui prétend "apprendre de toi". Farzapedia est l'exemple qu'il cite, un wiki personnel en Markdown structuré comme Wikipedia, où chaque entrée est un artefact lisible par un humain autant que par un LLM.
Le signal ici n'est pas l'outil. C'est le principe : si tu ne peux pas ouvrir un fichier et voir ce que ton agent sait de toi, tu n'as pas de mémoire. Tu as une boîte noire.
1 800 fichiers Markdown en 11 mois
@byPawel a loggé chaque session IA depuis mai 2025 dans un système pur Markdown. 1 800+ fichiers. Onze mois de prod.
Ce qu'il en tire n'est pas "j'ai une meilleure mémoire". C'est plus précis : forcer la documentation structurée à chaque session change la qualité des prompts suivants, parce que le contexte devient cumulatif au lieu d'être réinitialisé à chaque conversation. Chaque fichier devient une brique de contexte réutilisable.
Pour quiconque construit des agents ou travaille sur des projets longs avec des LLMs, ce retour d'expérience est probablement le plus concret disponible aujourd'hui.
GitAgent : git comme backend de mémoire agent
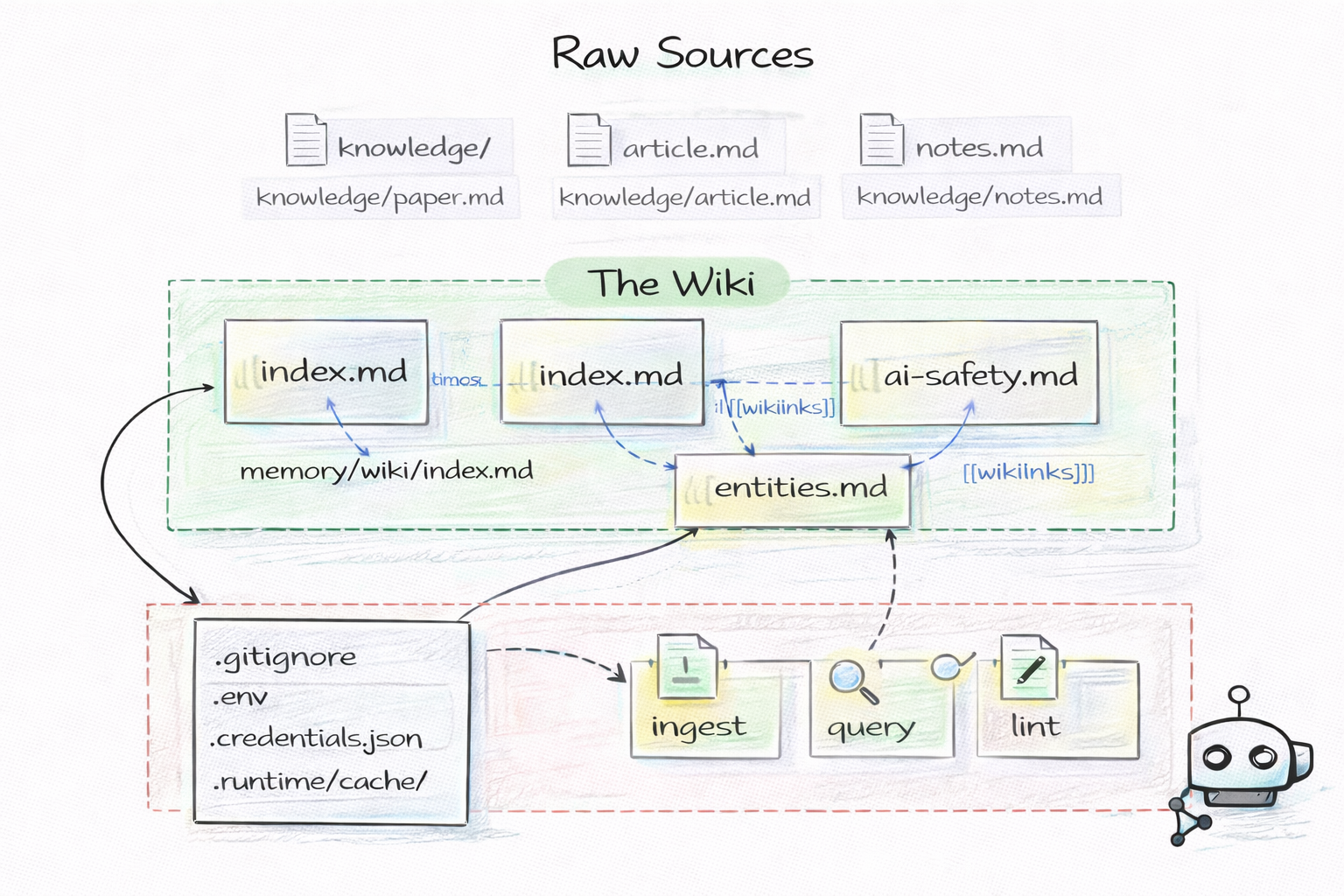
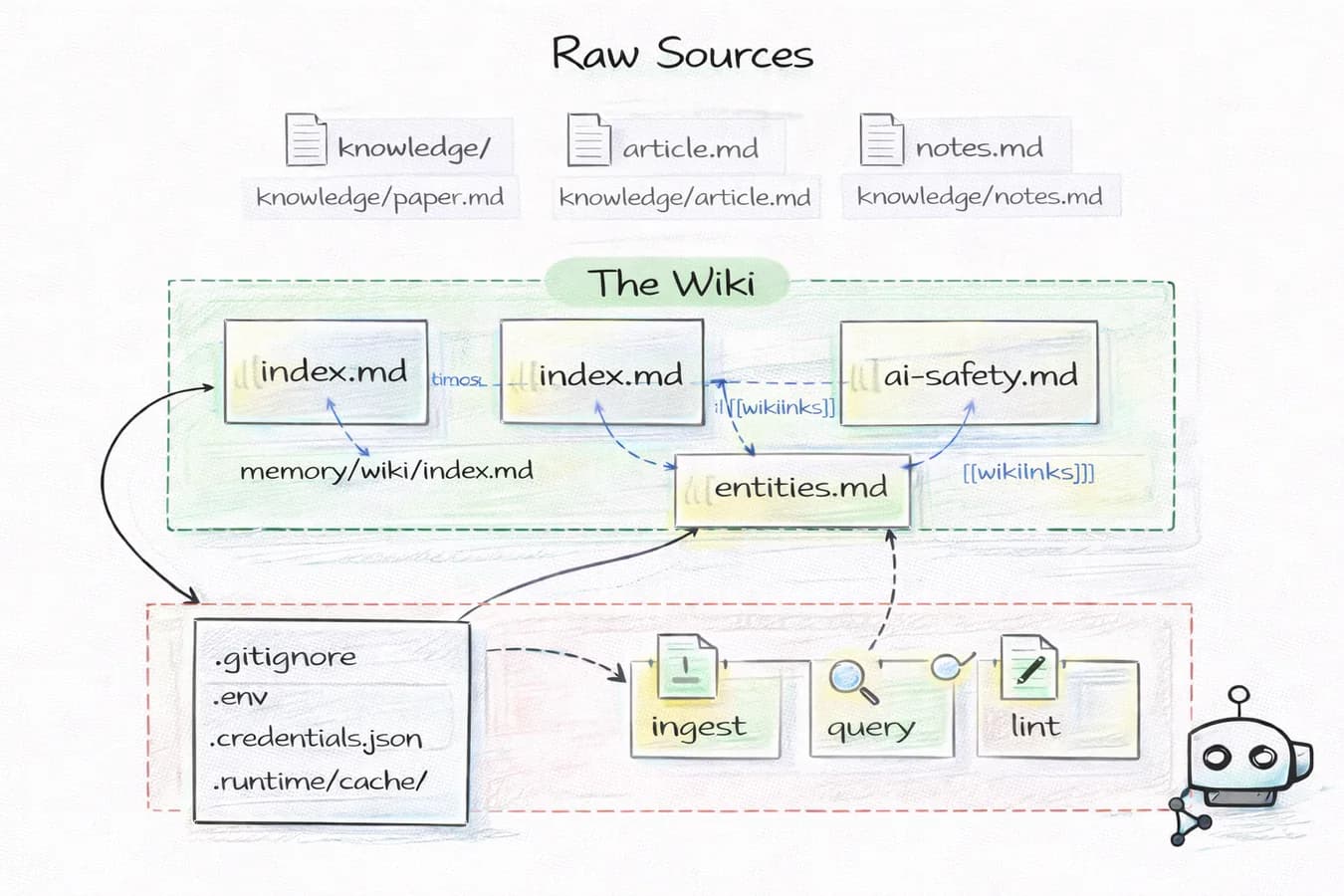
GitAgent pousse l'idée jusqu'au bout : la mémoire de l'agent est un repo git. Dossier knowledge/ pour les relations entre entités avec embeddings, dossier memory/ pour les logs runtime et décisions clés, et un système de lint qui vérifie la cohérence des pages wiki avant commit.
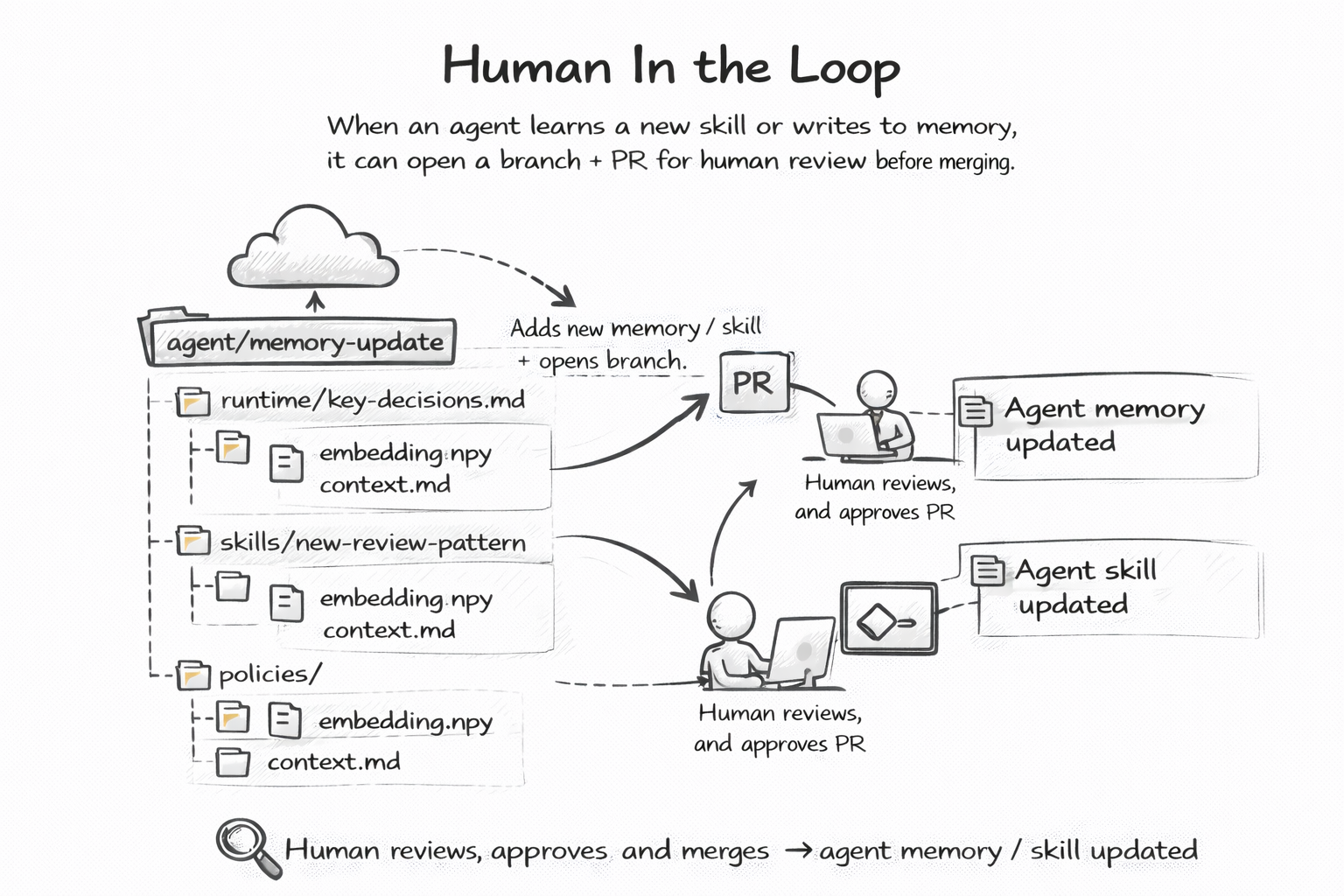
Le human-in-the-loop est architecturé via des PRs. L'agent crée une branche, propose un changement de mémoire ou de skill, et tu review avant merge. Rollback en cas de régression. C'est du context engineering avec les mêmes outils qu'un vrai projet logiciel.
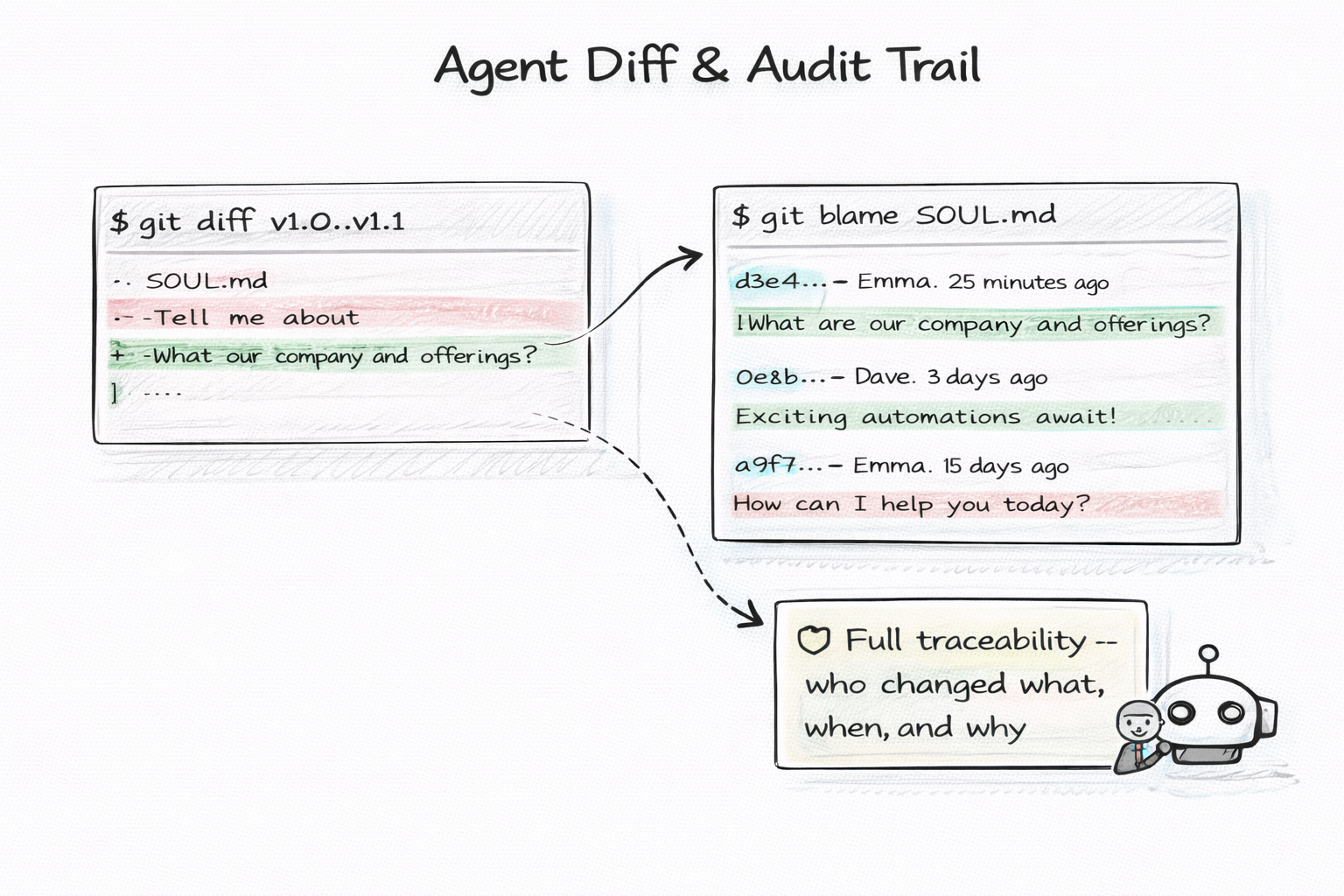
Pour des agents qui tournent sur des tâches longues, l'audit trail via git diff et git blame change la nature du debug : tu sais exactement quand la mémoire a divergé.
AKF : l'EXIF pour les fichiers IA
Dès qu'on gère des wikis LLM à grande échelle, une question émerge naturellement : comment savoir si un fichier .md est fiable, d'où il vient, et s'il est périmé ?
AKF (repo open-source, MIT) répond en embarquant des trust scores, de la provenance et des métadonnées de compliance directement dans le fichier, comme EXIF dans une photo. Ça s'installe en une commande :
pip install akf
eval $(akf shell-hook)
Après ça, chaque fichier touché par un agent reçoit automatiquement un stamp. L'audit se lance avec akf audit report.pdf. Ça couvre 30+ formats (DOCX, PDF, images, code, vidéo) et intègre des checks EU AI Act et HIPAA.
Table of Contexts : structurer le contexte au lieu de le subir
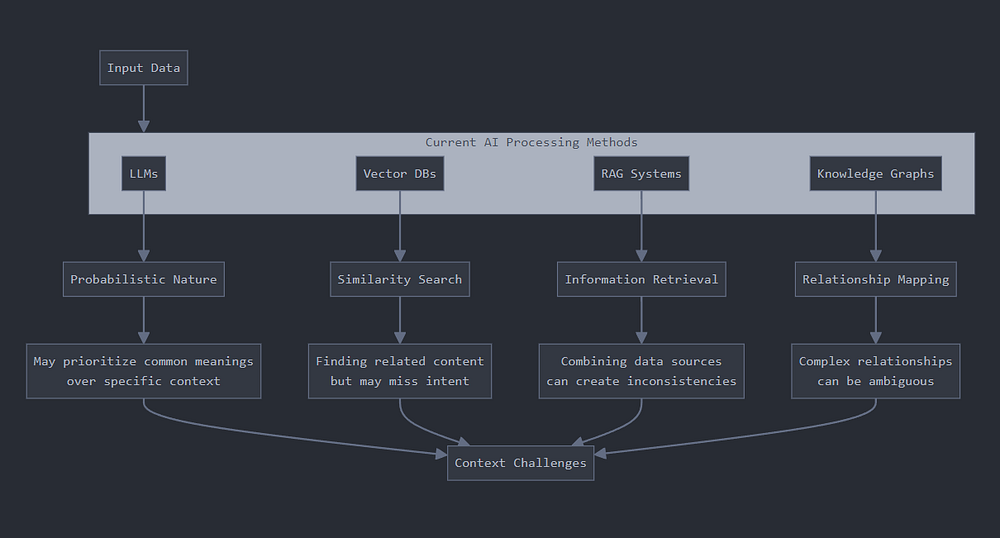
La Table of Contexts part d'un constat : laisser le LLM décider comment organiser l'information produit des résultats imprévisibles. L'alternative est de définir une structure de contexte explicite, une "table des matières du contexte" que l'agent suit plutôt qu'invente.
C'est moins spectaculaire qu'AKF ou GitAgent, mais c'est la couche de design qui conditionne tout le reste. Si tu travailles sur du context engineering depuis 2024, tu as probablement réinventé une variante de ça sans le formaliser.
Ces cinq directions convergent vers la même conclusion : la mémoire IA utile en 2025 est versionnable, auditable, et lisible par un humain. Pas une feature cachée dans un dashboard SaaS.
Communauté
Rejoins les builders IA
Tips, prompts, retours d'expérience. Le Telegram des gens qui buildent avec l'IA.