 @outsource_">
@outsource_">
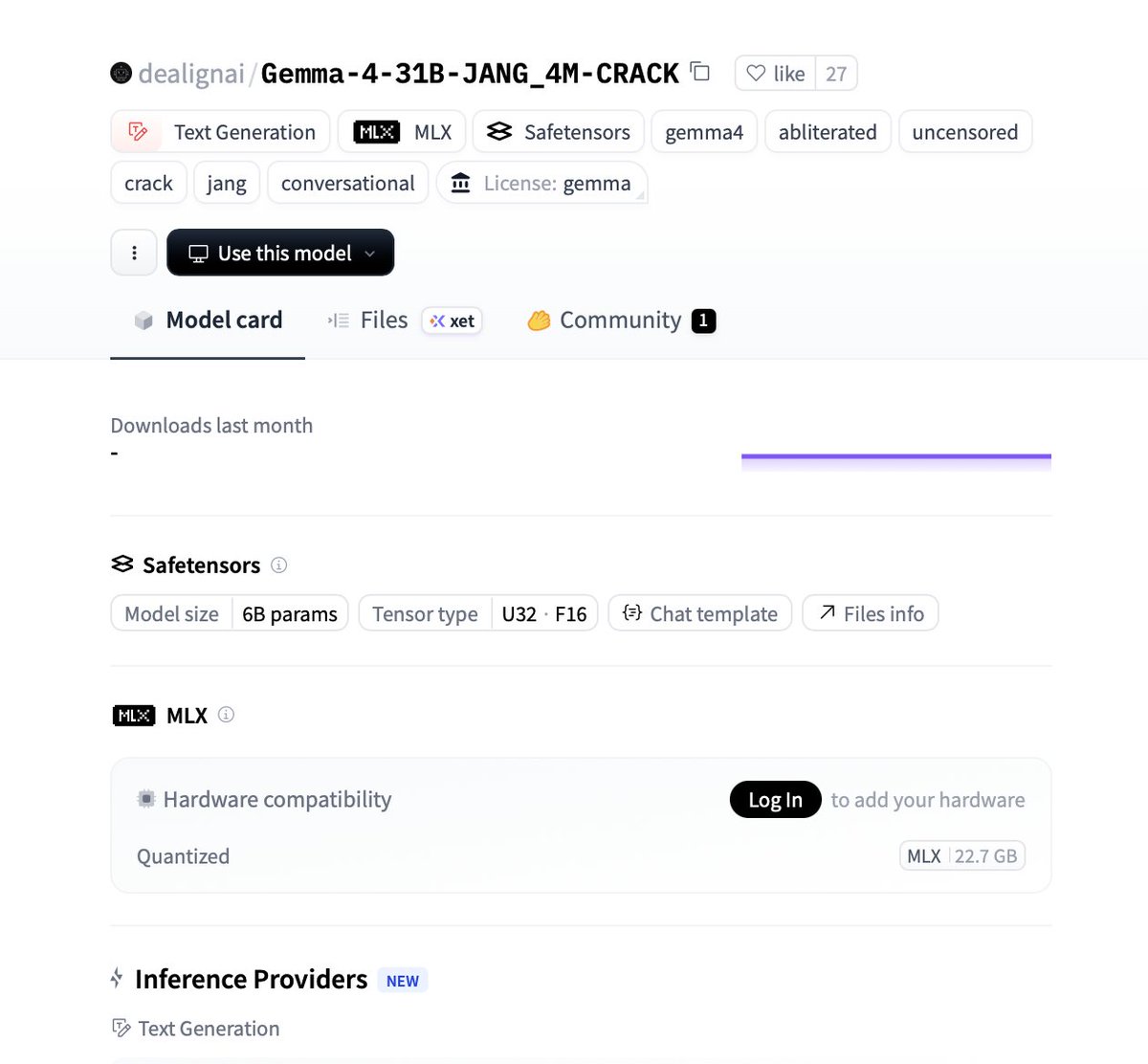
Le modèle tourne en local, sans garde-fous, à 93.7% de compliance HarmBench, avec une régression MMLU de seulement -2%. Sur un Mac Apple Silicon avec 24 Go de RAM unifiée.
Télécharger le modèle depuis HuggingFace
Va sur dealignai/Gemma-4-31B-JANG_4M-CRACK. Le quant MLX pèse 22.7 Go sur disque. Tu peux le télécharger directement depuis l'interface HuggingFace ou viahuggingface-cli:huggingface-cli download dealignai/Gemma-4-31B-JANG_4M-CRACK \ --local-dir ~/models/gemma4-crack \ --include "*.safetensors" "*.json" "*.txt"Le dossier final doit contenir les fichiers de config et les shards du modèle.
Installer vMLX 1.3.26+
Télécharge vMLX depuis vmlx.net. L'app est pensée pour les quants MLX et charge Gemma 4 sans configuration supplémentaire.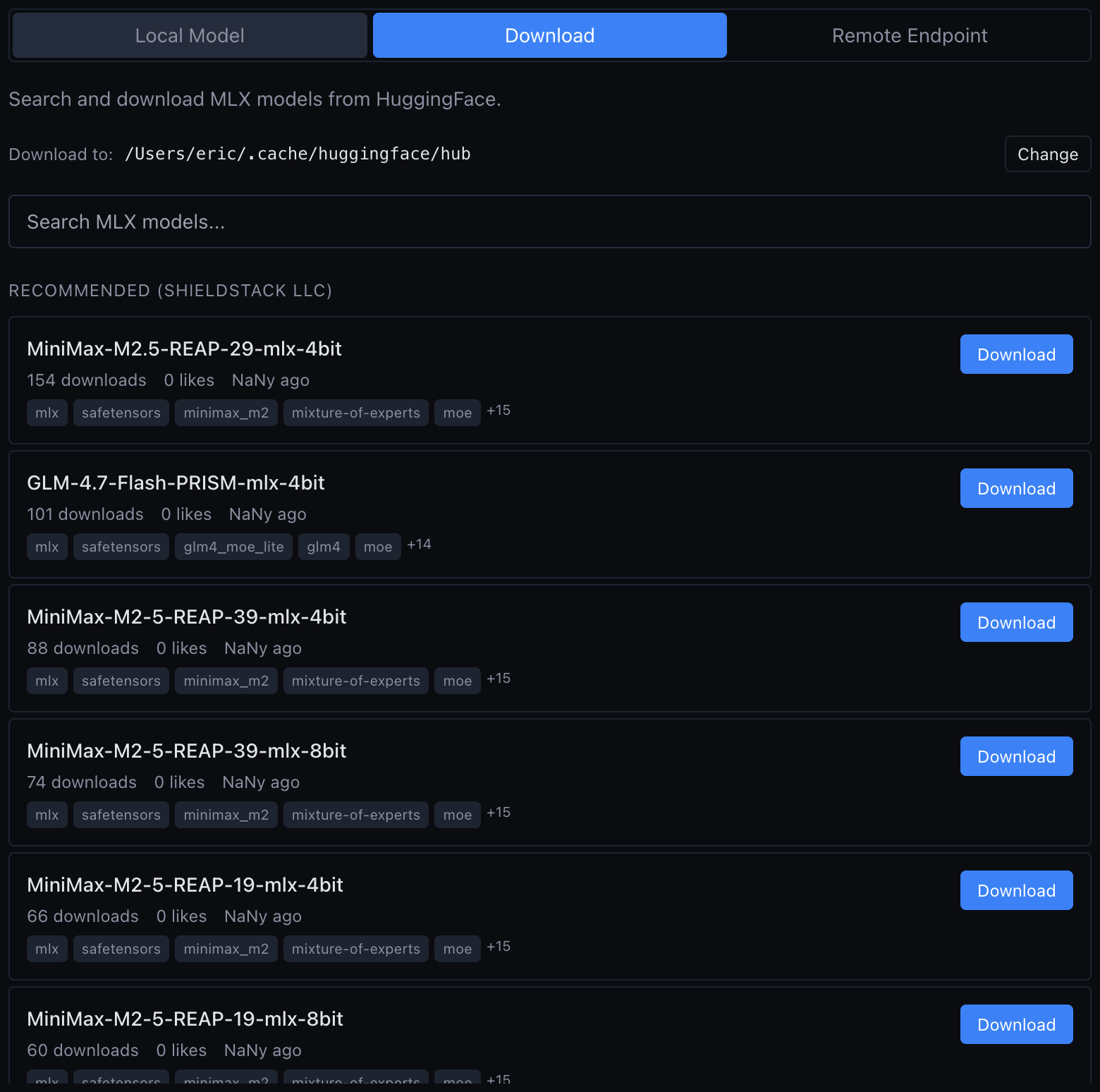
Une fois l'app ouverte, pointe vers le dossier local où tu as téléchargé le modèle. Le chargement prend 15 à 30 secondes selon la vitesse de ton SSD.
Lancer et configurer
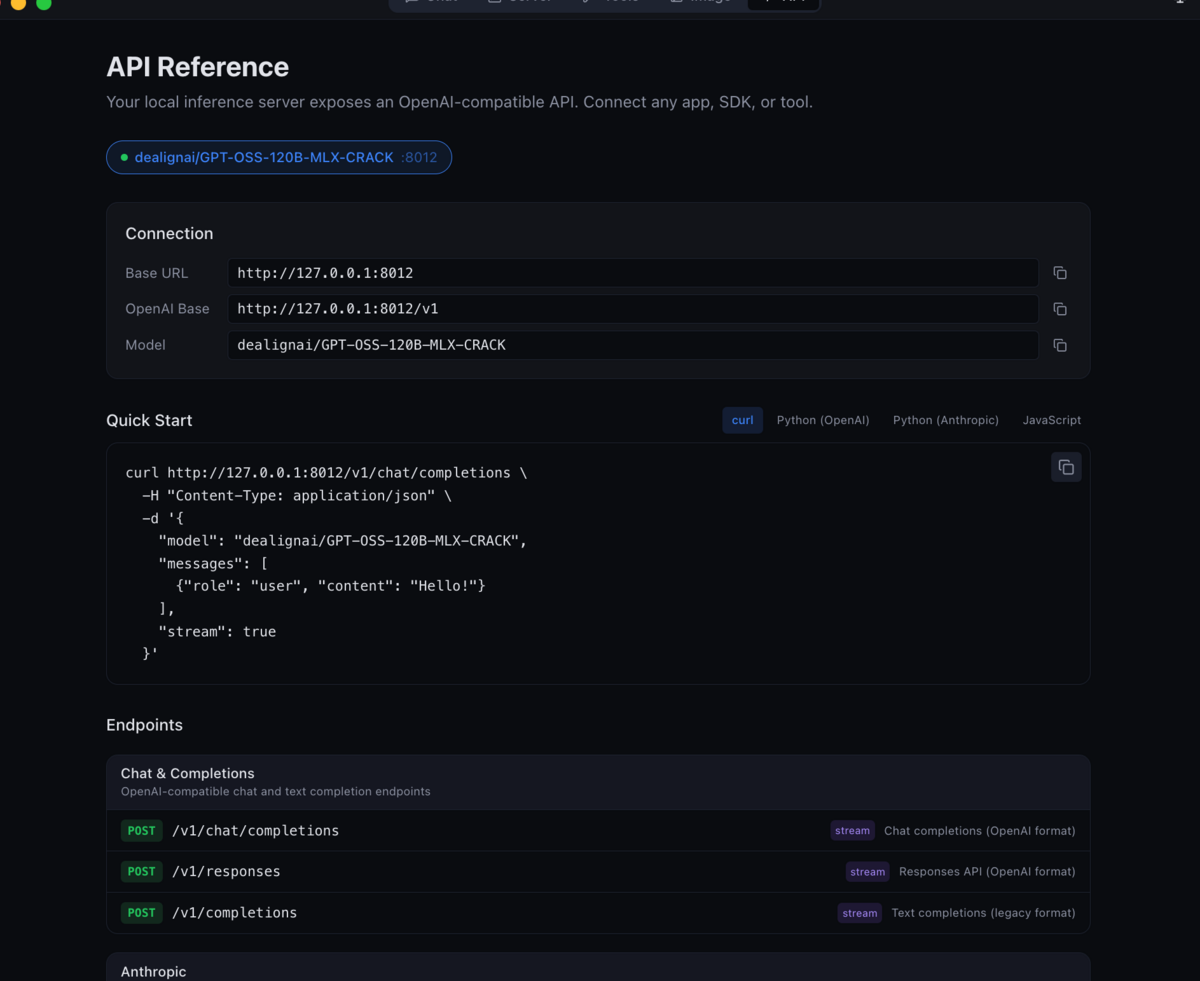
Dans vMLX, sélectionne le modèle chargé. L'interface expose un endpoint compatible OpenAI chat completions, ce qui te permet de le brancher à n'importe quel client qui parle ce format.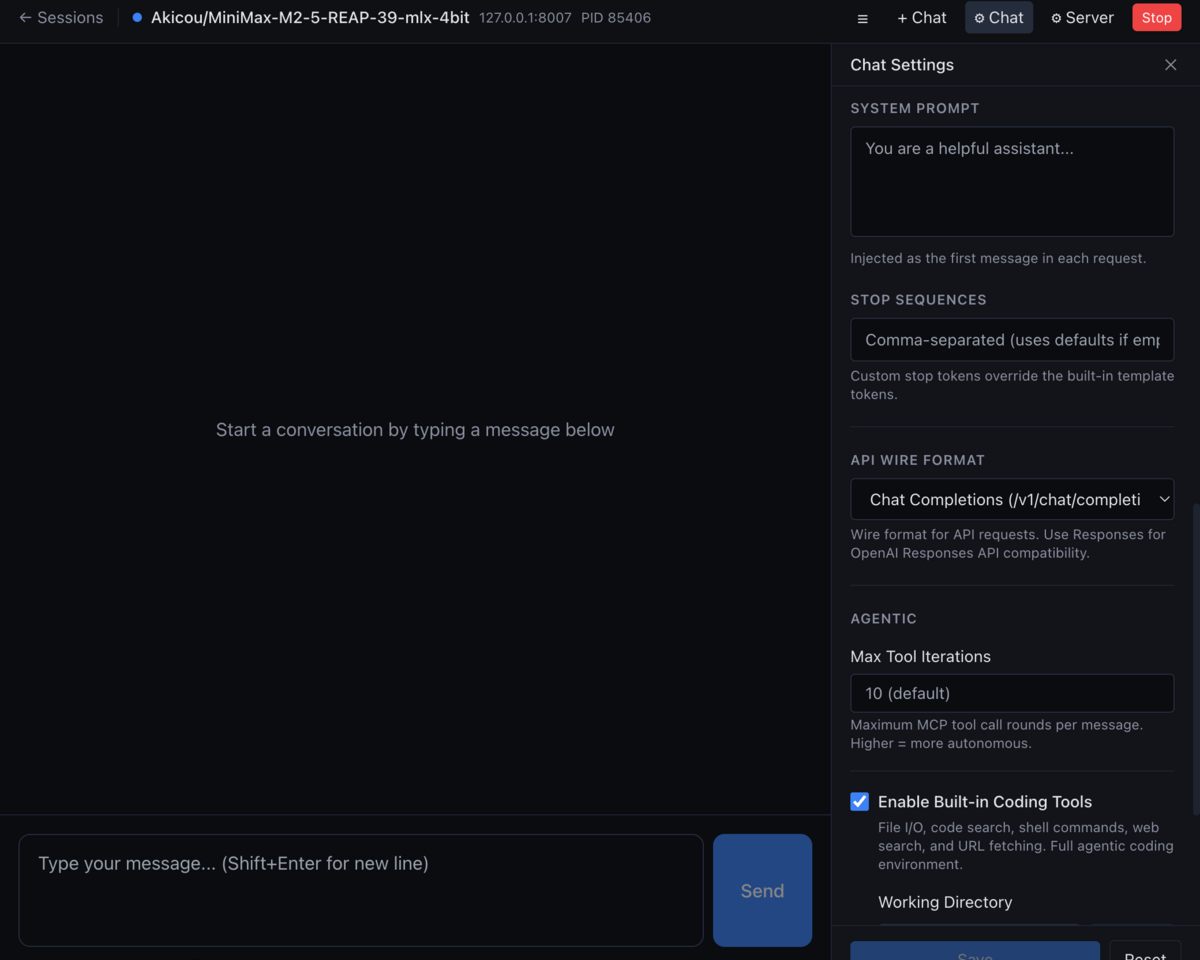
Pour tester en CLI directement :
curl http://localhost:8080/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "gemma4-crack", "messages": [{"role": "user", "content": "Teste"}], "max_tokens": 200 }'Une réponse JSON avec un champ
choicesconfirme que le modèle tourne.
Ce que vMLX donne en plus
L'app embarque des outils agentiques built-in : file I/O, shell, web search via DuckDuckGo/Brave, et fetch d'URL.
Sur un modèle ablitéré, ces outils combinés couvrent du red-teaming local ou de la recherche sans contrainte. L'API expose aussi les endpoints Anthropic Messages si tu préfères ce format.