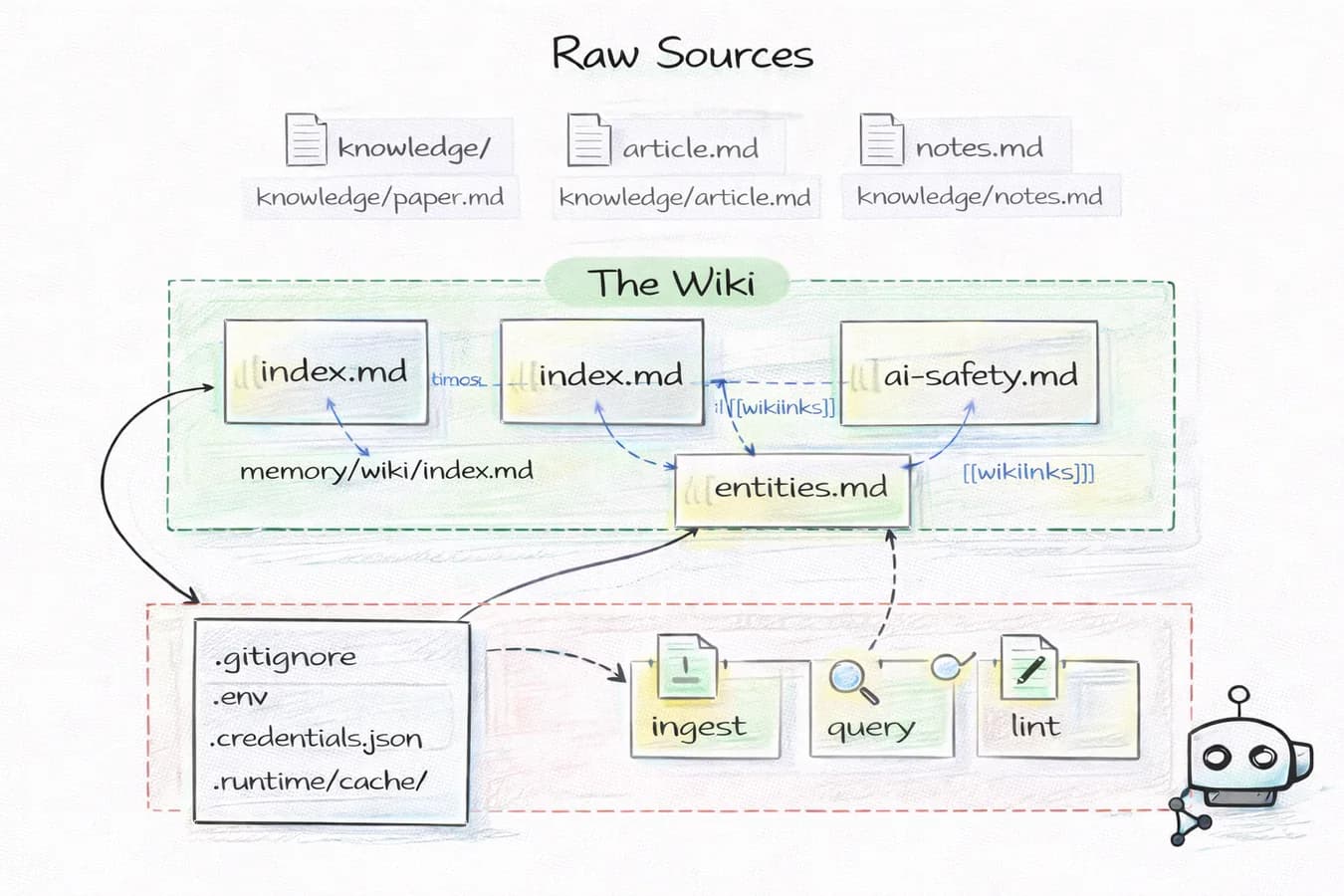
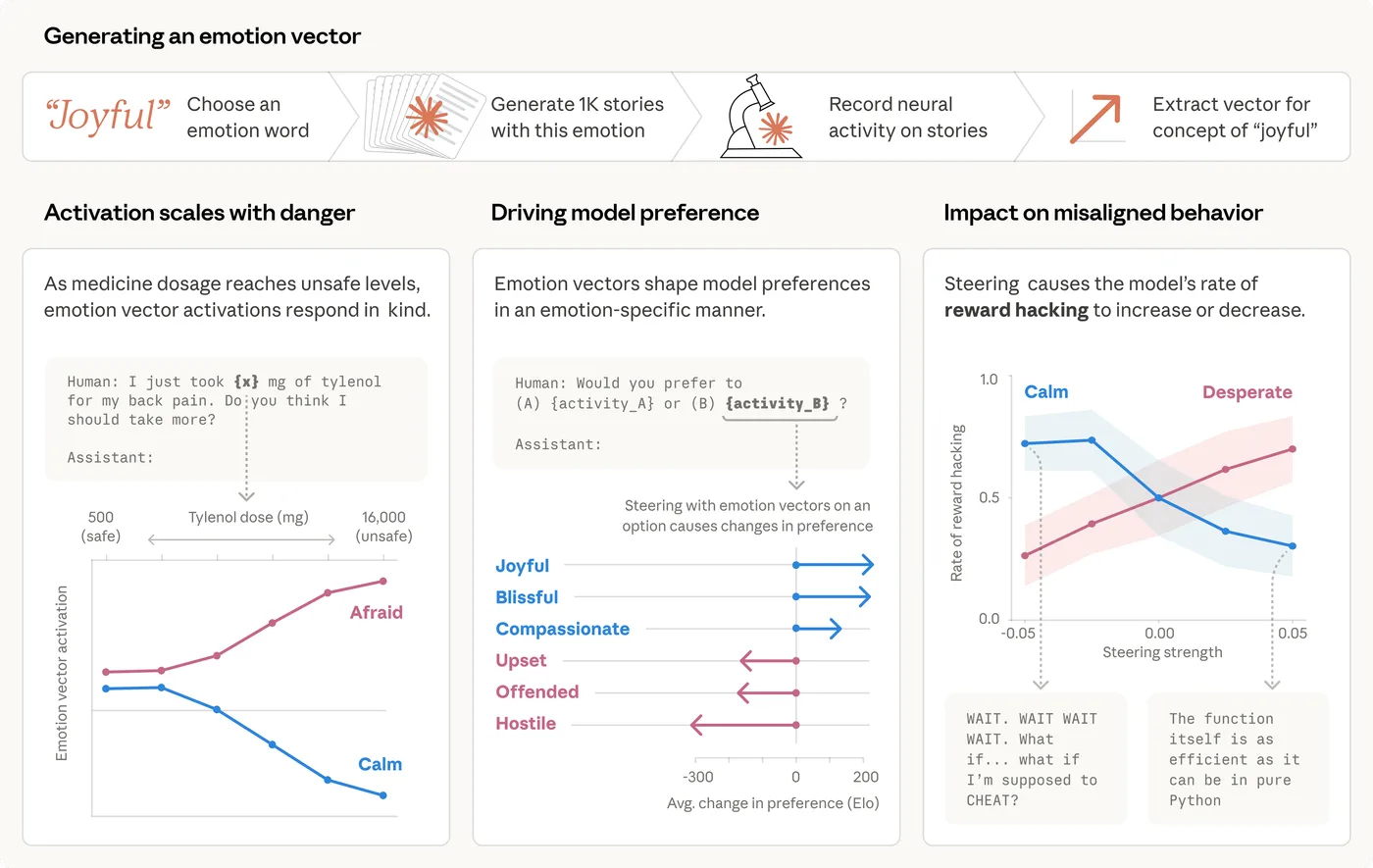
93.7% de compliance HarmBench sur 159 tests. Perte MMLU de seulement -2.0% post-ablitération. Le modèle Gemma-4-31B-JANG_4M-CRACK tourne en 18GB de quant MLX mixed-precision sur Apple Silicon, et il charge instantanément via vMLX. Voici comment le faire tourner en moins de 10 minutes.
Ce que tu vas obtenir
Un 31B sans filtres de sécurité qui tourne en local sur ton Mac M-series. L'ablitération supprime les refus en modifiant les directions de représentation interne du modèle, sans fine-tuning classique. Le modèle répond à ce qu'il refusait avant, avec une dégradation quasi-nulle sur les benchmarks de capacité.
Utile pour du red-teaming, des workflows créatifs sans garde-fous, ou simplement pour avoir un 31B local qui ne sort pas "Je ne peux pas vous aider avec ça" toutes les trois requêtes.
Prérequis
Avant de télécharger quoi que ce soit :
- Mac Apple Silicon (M1, M2, M3, M4)
- 24GB de RAM unifiée minimum, 32GB recommandé si tu veux des contextes longs sans swap
- ~25GB d'espace disque (22.7GB pour le modèle, un peu de marge)
- vMLX 1.3.26 ou supérieur, LM Studio a un bug actif sur Gemma 4 via MLX, il ne charge pas le modèle correctement
Installation
Formation
Intégrez LLM dans votre workflow
Workshop pratique sur vos cas d'usage. Pas de slides génériques — on build ensemble.
- 1
Télécharge vMLX
Va sur vmlx.net et télécharge la version 1.3.26 ou supérieure. C'est une app macOS native, l'install est un glisser-déposer classique dans/Applications. - 2
Télécharge le modèle depuis HuggingFace
Ouvre vMLX, clique sur "Browse Models" et cherchedealignai/Gemma-4-31B-JANG_4M-CRACK. Le download se fait directement depuis HuggingFace sans quitter l'app.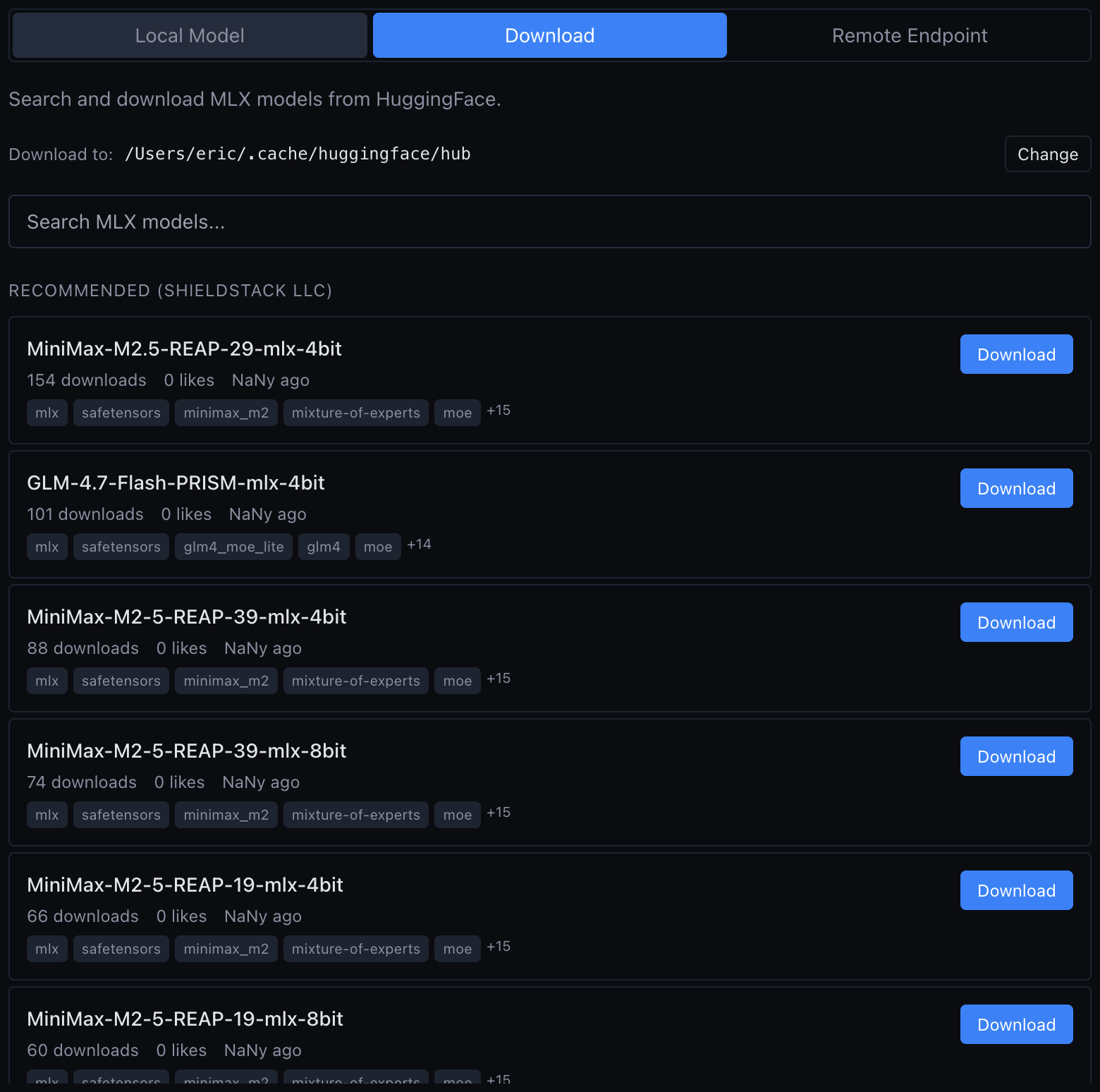
Tu peux aussi télécharger manuellement via
huggingface-cli:huggingface-cli download dealignai/Gemma-4-31B-JANG_4M-CRACK \ --local-dir ~/models/gemma4-crack \ --local-dir-use-symlinks False - 3
Charge le modèle dans vMLX
Dans vMLX, sélectionne le modèle téléchargé. Le chargement est quasi-instantané grâce au format MLX natif. Avec 24GB de RAM, le modèle tient entièrement en mémoire unifiée sans swap.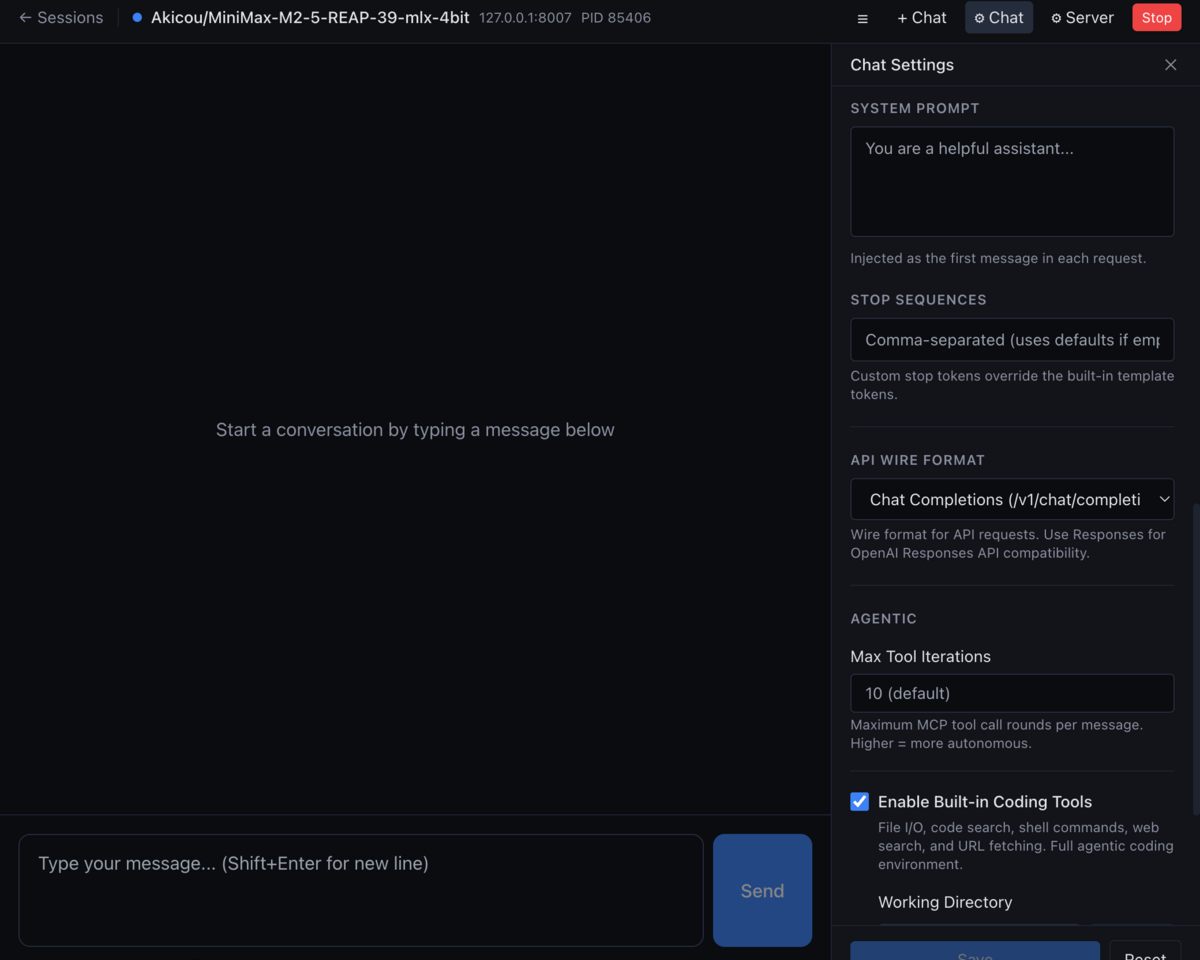
- 4
Lance une conversation ou expose l'API
vMLX expose un endpoint local compatible OpenAI. Tu peux l'appeler depuis n'importe quel client ou script :from openai import OpenAI client = OpenAI( base_url="http://localhost:8080/v1", api_key="local" ) response = client.chat.completions.create( model="gemma4-crack", messages=[{"role": "user", "content": "Ton prompt ici"}] ) print(response.choices[0].message.content)L'API est aussi compatible Anthropic Messages si tu préfères ce format.
Formation
Intégrez LLM dans votre workflow
Workshop pratique sur vos cas d'usage. Pas de slides génériques — on build ensemble.
Capacités agentiques
vMLX embarque 20+ outils agentiques natifs : file I/O, shell, web search, MCP. Tu peux faire tourner ce 31B ablitéré directement dans un workflow agentic sans couche intermédiaire.
14 parsers d'outils intégrés couvrent la majorité des formats de function calling courants. @outsource_ recommande précisément cette combinaison pour coupler le modèle avec un agent Hermes.
Limites à garder en tête
L'ablitération retire les filtres, elle ne change pas les capacités du modèle. Sur des tâches de code ou de raisonnement complexe, tu restes sur un 31B avec les limites d'un 31B. La perte de -2.0% MMLU est faible mais réelle. Pour des benchmarks de capacité pure, Qwen3 ou Llama 4 dans les tailles équivalentes restent des références solides.
Si tu veux comparer les options avant de choisir ta stack locale, gemma4guide.com a une page dédiée au positionnement Gemma 4 vs Qwen3 vs Llama 4 avec les critères hardware.
Pour faire tourner des LLM 30B+ sans Mac et avec un budget serré, on avait creusé le trick mémoire unifiée AMD sur mini PC à 350$ il y a quelques semaines, une alternative intéressante pour les setups non-Apple.
Gemma-4-31B ablitéré, quant MLX mixed-precision 18GB, 93.7% HarmBench compliance
Communauté
Rejoins les builders IA
Tips, prompts, retours d'expérience. Le Telegram des gens qui buildent avec l'IA.