96.6% sur LongMemEval. Meilleur score publié, toutes catégories confondues, gratuit. Cinq commandes et ton Claude ou ton Cursor retrouve la conversation où tu as choisi GraphQL plutôt que REST, il y a quatre mois.
Tu demandes "pourquoi on a switché sur GraphQL ?", Claude appelle mempalace_search en arrière-plan, et te répond avec le verbatim exact de la session où tu avais tranché. Zéro re-explication. Zéro contexte perdu.
MemPalace stocke tout, sans filtrer. Les autres systèmes de mémoire laissent le modèle décider ce qui vaut la peine d'être gardé : tu gardes "préfère Postgres" et tu perds la conversation où tu as expliqué pourquoi. Ici, chaque mot reste.
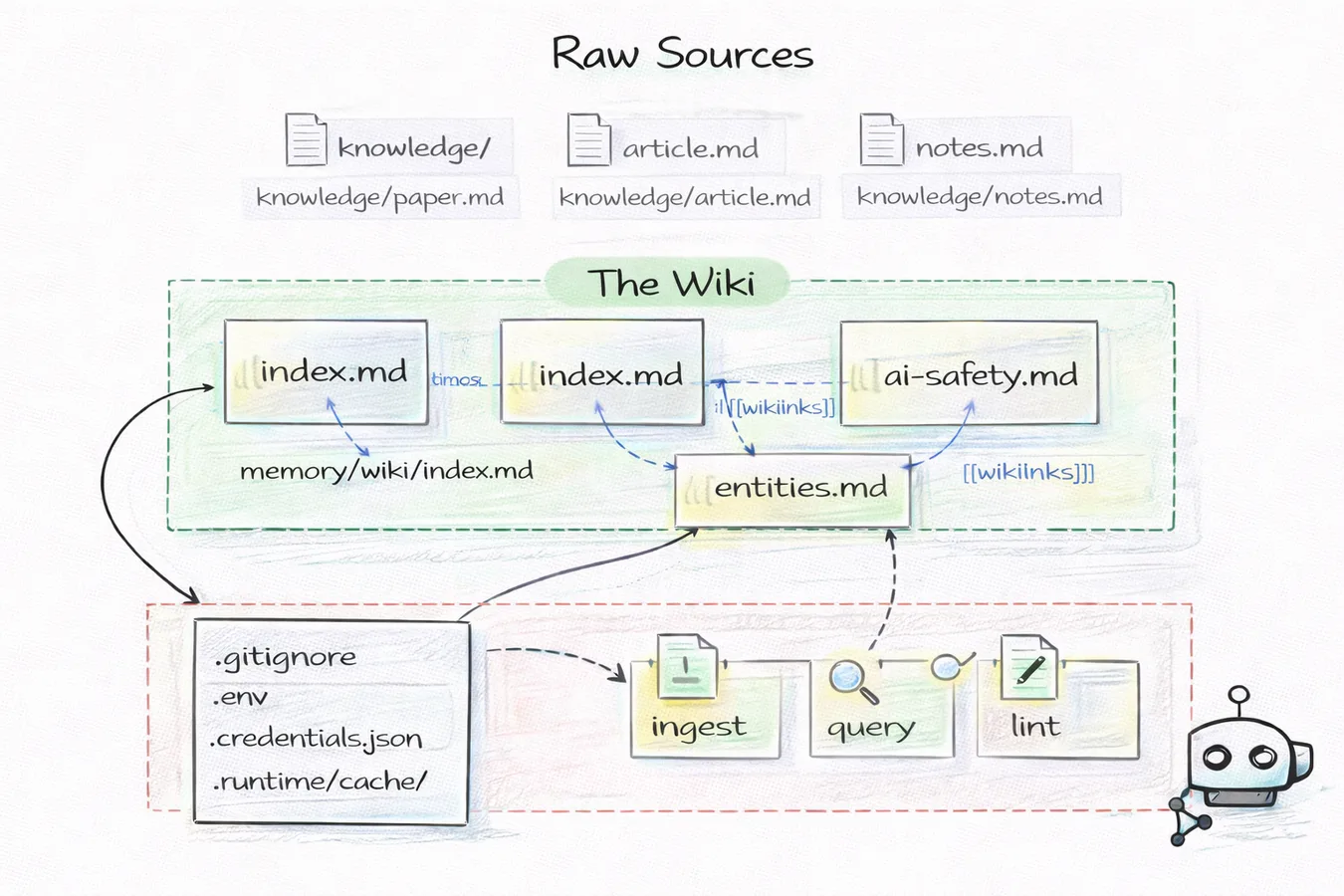
La structure s'inspire des orateurs grecs de l'Antiquité qui mémorisaient des discours entiers en imaginant des bâtiments. MemPalace organise tes conversations en wings (personnes et projets), halls (types de mémoire) et rooms (idées spécifiques). C'est cette hiérarchie qui produit les +34% de retrieval par rapport à un stockage plat.
La compression repose sur AAAK, un dialecte texte structuré conçu pour être lu par un modèle, vite. 30x de compression, zéro perte d'information. Six mois de contexte quotidien tiennent en ~170 tokens. Ça tourne sur n'importe quel modèle qui lit du texte : Claude, GPT, Llama, Mistral. Aucun fine-tuning, aucun décodeur, aucune API cloud.
Installation en 5 commandes
01
Installer le package
pip install mempalace
Python 3.9+ requis. Aucune dépendance cloud.
02
Initialiser ton espace de travail
mempalace init ~/projects/myapp
Tu définis ici qui tu es, avec qui tu travailles, quels projets existent. C'est le "palace" : la structure dans laquelle tout va s'organiser.
03
Miner tes données
Trois modes selon ce que tu as à disposition :
# Code, docs, notes d'un projet
mempalace mine ~/projects/myapp
# Exports de conversations (Claude, ChatGPT, Slack)
mempalace mine ~/chats/ --mode convos
# Classification automatique : décisions, milestones, problèmes, contexte émotionnel
mempalace mine ~/chats/ --mode convos --extract general
Lance les trois si tu as les données. Tout reste en local, rien ne sort de ta machine.
04
Vérifier que tout est là
mempalace status
Tu vois combien de rooms sont indexées, quels wings existent, l'état du vector store (ChromaDB local).
05
Tester la recherche
mempalace search "why did we switch to GraphQL"
Si tu obtiens un résultat verbatim d'une session passée, le setup est bon.
Connecter Claude ou Cursor via MCP
Une seule commande, une seule fois :
claude mcp add mempalace -- python -m mempalace.mcp_server
Après ça, 19 outils MCP sont disponibles dans Claude. Tu poses une question en langage naturel, Claude appelle mempalace_search lui-même et te répond avec les sources. Plus besoin de taper mempalace search à la main.
Cursor et ChatGPT fonctionnent de la même façon : n'importe quel client compatible MCP.
Avec un modèle local (Llama, Mistral, ou autre)
Les modèles locaux ne parlent pas encore MCP en général. Deux options selon ton workflow.
Option 1, Wake-up au démarrage de session :
mempalace wake-up > context.txt
# Colle context.txt dans le system prompt de ton modèle local
~170 tokens de faits critiques en AAAK, chargés avant la première question. Ton modèle arrive en session avec six mois de contexte.
Option 2, Recherche à la demande :
mempalace search "auth decisions" > results.txt
# Inclus results.txt dans ton prompt
Plus granulaire, utile quand tu sais exactement ce que tu cherches.
Ce que tu peux faire dès maintenant
Une fois le setup terminé, voilà les requêtes qui changent immédiatement le quotidien :
"What did we decide about auth last month?" : Claude retrouve la session, te cite la décision, te donne la date.
"Why did we switch to GraphQL?" : verbatim de la conversation où tu as tranché.
"What problems did we hit with the deploy pipeline?" : tous les incidents classifiés sous problems dans le mode general.
Le mining en mode --extract general est la partie qui mérite le plus d'attention. MemPalace auto-classifie chaque fragment en décisions, préférences, milestones, problèmes et contexte émotionnel. C'est ça qui rend les requêtes précises, au-delà de la recherche full-text.