- 01
Préparer le BIOS
Au démarrage, entre dans le BIOS et alloue le maximum autorisé au GPU (généralement 4 ou 8GB selon le firmware). Ce n'est pas le plafond réel, juste la valeur initiale que Vulkan va dépasser via GTT. Sauvegarde et redémarre sous Linux. - 02
Installer llama.cpp avec support Vulkan
Clone et compile avec le backend Vulkan activé :git clone https://github.com/ggerganov/llama.cpp cd llama.cpp cmake -B build -DGGML_VULKAN=ON cmake --build build --config Release -j$(nproc)Vérifie que Vulkan détecte bien le 780M :
./build/bin/llama-cli --list-devicesTu dois voir le Radeon 780M listé avec une VRAM reportée bien supérieure aux 4GB du BIOS.
- 03
Télécharger un modèle MoE quantifié
Les modèles denses ne passent pas à 20 tok/s sur ce hardware. Il faut du MoE. Deux options testées par la communauté :- Qwopus3.5-27B TurboQuant TQ3_4S : quantification TurboQuant spécifiquement optimisée pour hardware limité
- PolarQuant Gemma : collection Gemma4 quantifiée pour iGPU AMD
huggingface-cli download YTan2000/Qwopus3.5-27B-v3-TQ3_4S \ --local-dir ./models/qwopus-27b - 04
Lancer l'inférence avec offload GPU maximum
./build/bin/llama-server \ --model ./models/qwopus-27b/model.gguf \ --n-gpu-layers 99 \ --ctx-size 8192 \ --host 0.0.0.0 \ --port 8080Le flag
--n-gpu-layers 99force llama.cpp à offloader le maximum de layers vers le 780M. GTT prend le relais au-delà de l'allocation BIOS. Surveille la RAM système pendant le chargement : tu verras le GPU grignoter bien au-delà des 4GB affichés. - 05
Connecter à ton client ou agent
Le serveur expose une API compatible OpenAI surhttp://localhost:8080. Tu peux le brancher directement à n'importe quel client qui supporte une base URL custom : Open WebUI, Continue.dev, ou ton propre code.from openai import OpenAI client = OpenAI( base_url="http://localhost:8080/v1", api_key="local" ) response = client.chat.completions.create( model="qwopus-27b", messages=[{"role": "user", "content": "Hello"}] )

Ce que ça donne dans la pratique
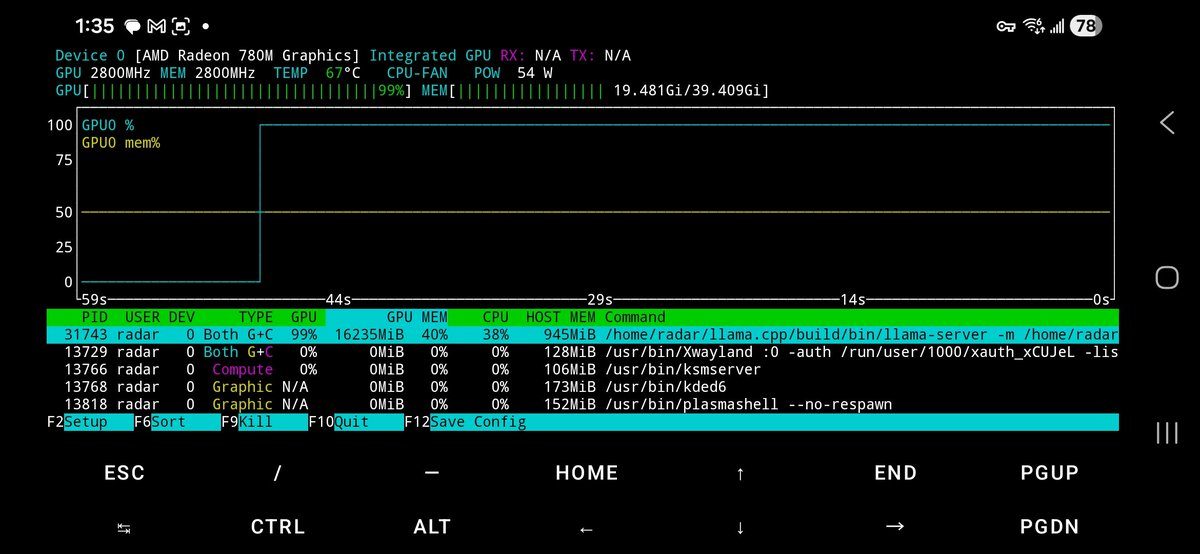
20 tok/s dépasse la vitesse de lecture confortable d'un humain. En mode chat, la latence perçue est nulle. En mode agentic avec web search, @basecampbernie note que les petits modèles "find what they don't know" : ils n'ont pas besoin de 100GB de poids sur l'histoire du monde si tu leur donnes accès à une recherche. Un Qwen3 26B en boucle agentic sur ce setup bat en pratique un modèle plus lourd qui tourne à 3 tok/s.
La consommation à 65W représente environ 570 kWh/an en 24/7, soit 80-100€ d'électricité selon ton tarif. À comparer avec n'importe quel abonnement API.
Modèle 27B quantifié avec l'algorithme TurboQuant, optimisé pour hardware à mémoire unifiée limitée.